ML Movie Recommendation System
Python
Matplotlib
Pandas
NumPy
scikit-learn
find this project on my Github page
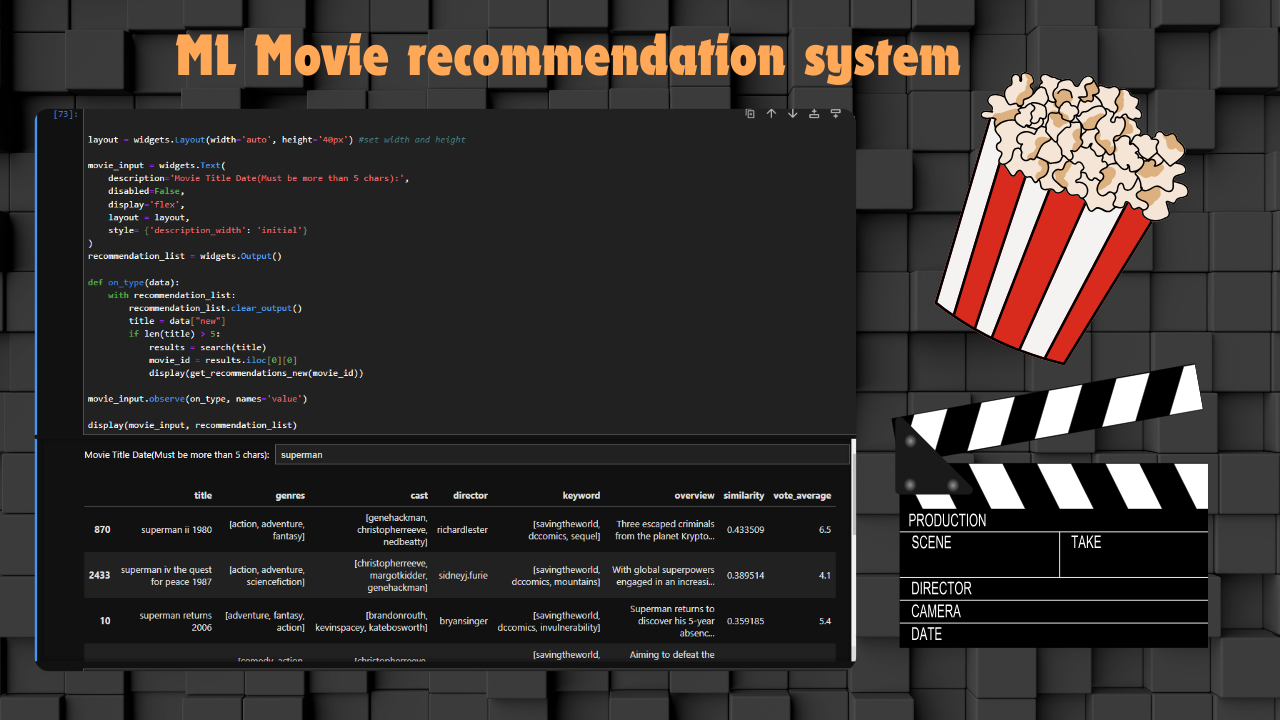
Short preview
Content-based movie recommendation system using machine learning
Goal: To use the tmdb data sets to create a recommendation system based on the movie name or part of it that is given to the functions get_recommendations or get_recommendations_new both functions use cosine similarity; the difference is, that the first one uses a cosine silmilarity matrix that is based on the countvectorizer matrix in which it uses the data of 'keywords' ,'cast','director,'genres' of each movie as the input to it.
On the other hand, the get_recommendations_new function uses the first method's cosine similarity + the cosine similarity of TF-IDF vectorizer matrix based on the movie overview; that is a short description of the movie, which in my opinion has more accurate results as it combines both cosine similarity aspects.
steps:
- Data pre-processing
- search engine creation
- recommendation system creation
We import the data using the pandas library and merge the two data sets that is; credits and movies based on the id which is a common column (foreign key) then we check for null values and deal with them separately.
# Open File
credits= pd.read_csv('tmdb_5000_credits.csv')
# Open File
movies= pd.read_csv('tmdb_5000_movies.csv')
#inspect the first 5 rows
movies.head(5)
#createing one big datset using the foreignkey "id"
credits.columns=['id','title','cast','crew']
movies=movies.merge(credits,on='id')
print("The Number of Null Values in Each Column:")
movies.isnull().sum()
#droping the homepage column as it has a lot of null values and it is not relavent
trainc=movies.drop(columns=['homepage'])
#remove the one row which had release date as null
trainc.drop(axis=0,index=trainc[trainc['release_date'].isnull()].index,inplace=True)
#replacing the runtime with the value f the runtime that has most occured
trainc['runtime'].fillna(trainc['runtime'].mode()[0],inplace=True)
#replacing null values with the word unknown
trainc['tagline'].fillna('unknown',inplace=True)
#replacing null values with empty string
trainc['overview'].fillna('',inplace=True)
after dealing with null values we start making the data suitable for our machine learning count vectorizer and tf-idf by applying the literal_eval function to the columns: genres, keywords, cast, and crew. As they are in a JSON format we need to extract the required values in a list format.
trainc.genres = trainc.genres.fillna('[]').apply(literal_eval)
trainc.keywords = trainc.keywords.fillna('[]').apply(literal_eval)
trainc.cast = trainc.cast.fillna('[]').apply(lambda x: re.sub(r"^('?)|('?)$" ,"",x)).apply(literal_eval)
trainc.crew = trainc.crew.fillna('[]').apply(literal_eval)
#we loop through all the json values of the crew column and if the the value of the key "job" is dirctor then we will grab the value of the key "name"
def get_director(x):
for i in x:
if i['job'] == 'Director':
return i['name']
return np.nan
# Returns the list top 3 elements or entire list; whichever is more.
def get_list(x):
if isinstance(x, list):
names = [i['name'] for i in x]
#Check if more than 3 elements exist. If yes, return only first three. If no, return entire list.
if len(names) > 3:
names = names[:3]
return names
#Return empty list in case of missing/malformed data
return []
# Define new director, cast, genres and keywords features that are in a suitable form.
trainc['director'] = trainc['crew'].apply(get_director)
features = ['cast', 'keywords', 'genres']
for feature in features:
trainc[feature] = trainc[feature].apply(get_list)
trainc[['original_title', 'cast', 'director', 'keywords', 'genres']].head(3)
#Function to convert all strings to lower case and strip names of spaces
def clean_data(x):
if isinstance(x, list):
return [str.lower(i.replace(" ", "")) for i in x]
else:
#Check if director exists. If not, return empty string
if isinstance(x, str):
return str.lower(x.replace(" ", ""))
else:
return ''
# # Apply clean_data function to your features.
features = ['cast', 'keywords', 'director', 'genres']
for feature in features:
trainc[feature] = trainc[feature].apply(clean_data)
Now we create the soup for our count vectorizer by concatenating all the values of the features separated by a space. and then we create the count vectorizer object and then fit our soup to it, after that, we create our cosine similarity matrix. and we fit the overview to the tf-idf vectorizer and compute the linear kernel.
def create_soup(x):
return ' '.join(x['keywords']) + ' ' + ' '.join(x['cast']) + ' ' + x['director'] + ' ' + ' '.join(x['genres'])
trainc['soup'] = trainc.apply(create_soup, axis=1)
from sklearn.feature_extraction.text import CountVectorizer
#we fit the soup to our count vectorizer
count = CountVectorizer(stop_words='english')
count_matrix = count.fit_transform(trainc['soup'])
# Compute the Cosine Similarity matrix based on the count_matrix
from sklearn.metrics.pairwise import cosine_similarity
cosine_sim2 = cosine_similarity(count_matrix, count_matrix)
# Reset index of our main DataFrame and construct reverse mapping as before
trainc = trainc.reset_index()
indices = pd.Series(trainc.index, index=trainc['original_title'])
from sklearn.feature_extraction.text import TfidfVectorizer
#Define a TF-IDF Vectorizer Object. Remove all english stop words such as 'the', 'a'
tfidf = TfidfVectorizer(stop_words='english')
#Replace NaN with an empty string
trainc['overview'] = trainc['overview'].fillna('')
#Construct the required TF-IDF matrix by fitting and transforming the data
tfidf_matrix = tfidf.fit_transform(trainc['overview'])
#Output the shape of tfidf_matrix
tfidf_matrix.shape
from sklearn.metrics.pairwise import linear_kernel
# Compute the cosine similarity matrix
cosine_sim = linear_kernel(tfidf_matrix, tfidf_matrix)
This is the part where we create the search engine by utilizing the ipywigets and benefitting from their interactivity. initially, we cleaned and tuned the original title by adding the date and removing any character that is not English, then we fit the titles to the tf-idf vectorizer and tuned it to be a two-word bag of words so it takes the title and the date and separates it into pairs. and finally, we use the search engine to find the most similar movie to the searched title and then we get the index of this movie and use the combination of the cosine similarity matrix and the linear kernel matrix to find the list of movies that are most similar to the searched one. hence we recommend the top 10 movies that have the highest similarity score.
trainc['year'] = pd.to_datetime(trainc['release_date'], errors='coerce').apply(lambda x: str(x).split('-')[0] if x != np.nan else np.nan)
#add the Release Year to the movie title to create a search engine using jupyter notebook widgets.
trainc["original_title"]=trainc['original_title']+" "+trainc["year"]
#removing any character other than numbers and English letters
import re
def clean_title(title):
title = re.sub("[^a-zA-Z0-9 ]", "", title)
title=title.lower()
return title
trainc["cleaned_title"]=trainc["original_title"].apply(clean_title)
#this will take the title as sets of two words (bag of 2)
vectorizer = TfidfVectorizer(ngram_range=(1,2))
tfidf = vectorizer.fit_transform(trainc["cleaned_title"])
def search(title):
#we clean the title that the user will input in the field
title = clean_title(title)
#we transform it using the tf-idf vectorizor
query_vec = vectorizer.transform([title])
#computing the cosine sim between the vector of the user title and the tfidf matrix
similarity = cosine_similarity(query_vec, tfidf).flatten()
# indices = np.argpartition(similarity, -5)[-5:]
indices=list(enumerate(similarity))
indices=sorted(indices,reverse=True,key=lambda x : x[1])
indices=[i[0] for i in indices[:5]]
results = trainc[['index','original_title','cleaned_title', 'cast', 'director', 'keywords', 'genres']].iloc[indices]
return results
# Function that takes in movie title as input and outputs most similar movies
def get_recommendations_new(idx):
# Get the index of the movie that matches the title
# t=b[b["original_title"].str.lower().str.contains(str(title).lower())]["original_title"].values[0]
# idx = indices[t]
# Get the pairwsie similarity scores of all movies with that movie
sim_scores = list(enumerate((cosine_sim[idx]+cosine_sim2[idx])/2))
# Sort the movies based on the similarity scores
sim_scores = sorted(sim_scores, key=lambda x: x[1], reverse=True)
# Get the scores of the 10 most similar movies
sim_scores = sim_scores[1:11]
# Get the movie indices
movie_indices = [i[0] for i in sim_scores]
#cosformovies
movie_sim = [i[1] for i in sim_scores]
# Return the top 10 most similar movies
ko={"title":trainc['cleaned_title'].iloc[movie_indices] ,"genres":trainc['genres'].iloc[movie_indices],"cast":trainc['cast'].iloc[movie_indices],'director':trainc['director'].iloc[movie_indices],'keyword':trainc['keywords'].iloc[movie_indices],'overview':trainc['overview'].iloc[movie_indices],'similarity':movie_sim,"vote_average":trainc['vote_average'].iloc[movie_indices]}
dms=pd.DataFrame(ko)
return dms
# Function that takes in movie title as input and outputs most similar movies
def get_recommendations_new(idx):
# Get the index of the movie that matches the title
# t=b[b["original_title"].str.lower().str.contains(str(title).lower())]["original_title"].values[0]
# idx = indices[t]
# Get the pairwsie similarity scores of all movies with that movie
sim_scores = list(enumerate((cosine_sim[idx]+cosine_sim2[idx])/2))
# Sort the movies based on the similarity scores
sim_scores = sorted(sim_scores, key=lambda x: x[1], reverse=True)
# Get the scores of the 10 most similar movies
sim_scores = sim_scores[1:11]
# Get the movie indices
movie_indices = [i[0] for i in sim_scores]
#cosformovies
movie_sim = [i[1] for i in sim_scores]
# Return the top 10 most similar movies
ko={"title":trainc['cleaned_title'].iloc[movie_indices] ,"genres":trainc['genres'].iloc[movie_indices],"cast":trainc['cast'].iloc[movie_indices],'director':trainc['director'].iloc[movie_indices],'keyword':trainc['keywords'].iloc[movie_indices],'overview':trainc['overview'].iloc[movie_indices],'similarity':movie_sim,"vote_average":trainc['vote_average'].iloc[movie_indices]}
dms=pd.DataFrame(ko)
return dms
by Michel Al-Haj
Comments (0)